
缓存更新策略
缓存更新策略
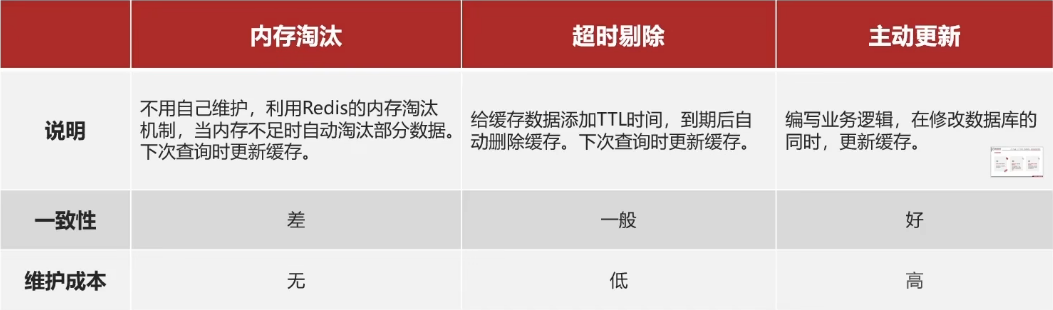
业务场景:
- 低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存
- 高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存
主动更新策略
旁路缓存模式(Cache Aside Pattern):由缓存的调用者,在更新数据库的同时更新缓存
逻辑
- 查询缓存,如果不存在那么就读取数据库并写入到缓存当中
- 如果是更新数据库,那么操作完数据库后,删除缓存.
特点:缓存中的内容不做更新操作,只有删除和写入操作
缺点:需要自己写,对调用者可能复杂
问题:
1,如何保证缓存与数据库的操作同时成功或失败
- 单体系统,将缓存与数据库操作放在一个事务中
- 分布式系统,利用
TCC等分布式事务方案
2,先操作缓存还是先操作数据库
①先删除缓存,再操作数据库
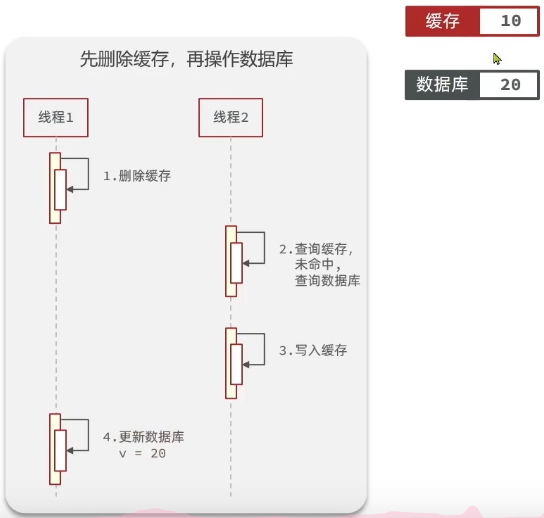
数据库值一开始为10,线程2查到的是10,随后写入缓存,线程1再进行更新操作,数据库中值改为20,这时就会出现缓存不一致的情况
这种情况出现概率挺高,因为线程1是删缓存,写数据库,线程2是读数据库,写缓存
②先操作数据库,再删除缓存
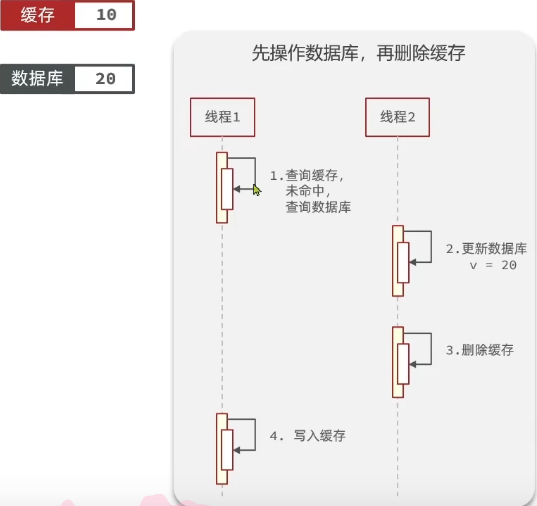
线程1先查数据库,这时线程2更新数据库,并删除缓存,线程1再写入缓存,就会出现缓存不一致的情况
概率较小,首先缓存要先失效,线程1再来读数据库,写缓存,再这个间隙,线程2写数据库,删缓存,由于线程1的用时很短,所以在这个时间内,线程2很难完成这些操作,所以比较可能的情况是,线程1完成后,数据库的值还是10,就算后面线程2要改,这时数据库和缓存还是一致的。
所以推荐使用②方案。
适用场景
- 用于读操作较多.实现简单
读写穿透模式(Read/Write Through Pattern):缓存与数据库整合为一个服务,由服务来维护一致性,调用者调用该服务,无需关心缓存一致性问题。
逻辑:以缓存为操作为主,数据存先存在于缓存,缓存的数据是不会过期的。
Read Through:先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据
Write Through:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做Write Miss(写失效)
Write Miss解决方式:一个是“Write Allocate(按写分配)”,做法是写入缓存相应位置,再由缓存组件同步更新到数据库中,图中就是指的是这种方式;另一个是“No- write allocate(不按写分配)”,做法是不写入缓存中,而是直接更新到数据库中
缺点:维护该服务,比较复杂,市面上现成服务比较难找,开发成本比较高
适用场景
- 用于读操作较多,相较于Cache aside而言更适合缓存一致的场景.
- 使用简单,屏蔽了底层数据库的操作,只是操作缓存.
- 可以以
Redis为存储,对数据的持久性要求较低的
异步回写策略(Write Behind Caching Pattern):使用者只操作缓存,由其它线程异步的将缓存数据持久化到数据库,保证最终一致
缺点:实现比较复杂,可能会丢失数据,一致性和可靠性较低
适用场景
- 用于读少写多的场景,Linux系统的页缓存和
MySQL InnoDB引擎的Cache Pool其实就是使用的WriteBack策略,相较于Write through 而言拥有更高的写入性能
主动更新策略中用的较多的是旁路缓存模式